





Web scraping is the art of extracting data from a website in an automated and well-structured form. There could be different formats for scraping data like excel, CSV, and many more. Some practical use cases of web scraping are market research, price monitoring, price intelligence, market research, and lead generation. Web scraping is an instrumental
Web scraping is the art of extracting data from a website in an automated and well-structured form. There could be different formats for scraping data like excel, CSV, and many more. Some practical use cases of web scraping are market research, price monitoring, price intelligence, market research, and lead generation. Web scraping is an instrumental technique to make the best use of publicly available data and make smarter decisions. So it’s great for everyone to know at least the basics of web scraping to benefit from it.
This article will cover web scraping basics by playing around with Python’s framework called Beautiful Soup. We will be using Google Colab as our coding environment.
Steps Involved in Web Scraping using Python
First of all, we need to identify the webpage we want to scrape and send an HTTP request to that URL. In response, the server returns the HTML content of the webpage. For this task, we will be using a third-party HTTP library to handle python-requests.Once we are successful in accessing the HTML content, the major task comes to the parsing of data. We can not process data simply through string processing since most of the HTML data is nested. That’s where the parser comes in, making a nested tree structure of the HTML data. One of the most advanced HTML parser libraries is html5lib.Next comes the tree traversal, which involves navigating and searching the parse tree. For this purpose, we will be using Beautiful Soup(a third-party python library). This Python library is used for pulling data out of HTML and XML files.
Now we have seen how the process of web scraping works. Let’s get started with coding,
Step1: Installing Third-Party Libraries
In most cases, Colab comes with already installed third-party packages. But still, if your import statements are not working, you can get this issue resolved by installing few packages by the following commands,
pip install requests
pip install html5lib
pip install bs4Step2: Accessing the HTML Content From the Webpage
import requests
URL = "http://www.values.com/inspirational-quotes"
r = requests.get(URL)
print(r.content)It will display the output of the form,

Let’s try to understand this piece of code,
In the first line of code, we are importing the requests library.Then we are specifying the URL of the webpage we want to scrape.In the third line of code, we send the HTTP request to the specified URL and save the server’s response in an object called r.Finally print(r.content) returns the raw HTML content of the webpage.
Step3: Parsing the HTML Content
import requests
from bs4 import BeautifulSoup
URL = "http://www.values.com/inspirational-quotes"
r = requests.get(URL)
soup = BeautifulSoup(r.content, 'html5lib') # If this line causes an error, run 'pip install html5lib' or install html5lib
print(soup.prettify())Output:
It gives a very long output; some of the screenshots are attached below.
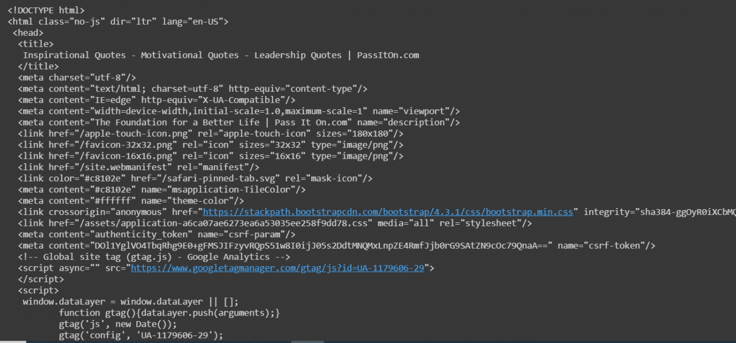
One of the greatest things about Beautiful Soup is that it is built on the HTML parsing libraries like html5lib, html.parse, lxml etc that allows Beautiful Soap’s object and specify the parser library to be created simultaneously.
In the code above, we have created the Beautiful Soup object by passing two arguments:
r.content: Raw HTML content.
html5lib: Specifies the HTML parser we want to use.
Finally, soup.prettify() is printed, giving the parse tree visual representation from the raw HTML content.
Step4: Searching and navigating the parse tree
Now it’s time to extract some of the useful data from the HTML content. The soup objects contain the data in the form of the nested structure, which could be further programmatically extracted. In our case, we are scraping a webpage consisting of some quotes. So we will create a program that solves these quotes. The code is given below,
#Python program to scrape website
#and save quotes from website
import requests
from bs4 import BeautifulSoup
import csv
URL = "http://www.values.com/inspirational-quotes"
r = requests.get(URL)
soup = BeautifulSoup(r.content, 'html5lib')
quotes=[] # a list to store quotes
table = soup.find('div', attrs = {'id':'all_quotes'})
for row in table.findAll('div', attrs = {'class':'col-6 col-lg-3 text-center margin-30px-bottom sm-margin-30px-top'}):
quote = {}
quote['theme'] = row.h5.text
quote['url'] = row.a['href']
quote['img'] = row.img['src']
quote['lines'] = row.img['alt'].split(" #")[0]
quote['author'] = row.img['alt'].split(" #")[1]
quotes.append(quote)
filename = 'inspirational_quotes.csv'
with open(filename, 'w', newline='') as f:
w = csv.DictWriter(f,['theme','url','img','lines','author'])
w.writeheader()
for quote in quotes:
w.writerow(quote)Before moving further, it is recommended to go through the HTML content of the webpage, which we printed using soup.prettify() method and try to find a pattern to navigate to the quotes.
Now I will explain how we get this done in the above code,
If we navigate through the quotes, we will find that all the quotes are inside a div container whose id is ‘all_quotes.’ So we find that div element (termed as table in the code) using find() method:
table = soup.find('div', attrs = {'id':'all_quotes'})The first argument in this function is that the HTML tag needed to be searched. The second argument is a dictionary type element to specify the additional attributes associated with that tag. find() method returns the first matching element. One may try table.prettify() to get a better feeling of what this piece of code does.
If we focus on the table element, the div container contains each quote whose class is quote. So we will loop through each div container whose class is quote.
Here the findAll() method is very useful that is similar to find() method as far as arguments are concerned, but the major difference is that it returns a list of all matching elements.
We are iterating through each quote using a variable called row.
Let’s analyze one sample of HTML row content for better understanding:
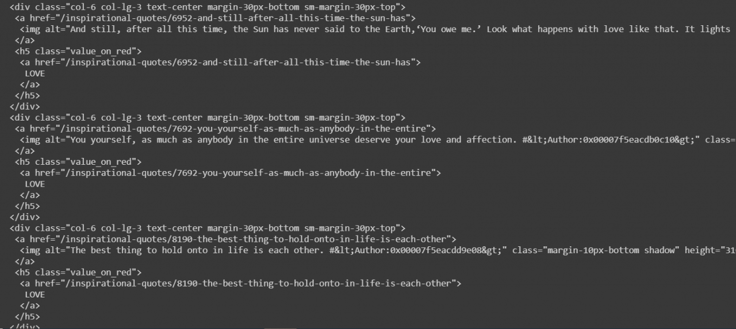
Now consider the following piece of code:
for row in table.findAll('div', attrs = {'class':'col-6 col-lg-3 text-center margin-30px-bottom sm-margin-30px-top'}):
quote = {}
quote['theme'] = row.h5.text
quote['url'] = row.a['href']
quote['img'] = row.img['src']
quote['lines'] = row.img['alt'].split(" #")[0]
quote['author'] = row.img['alt'].split(" #")[1]
quotes.append(quote)
filename = 'inspirational_quotes.csv'
with open(filename, 'w', newline='') as f:
w = csv.DictWriter(f,['theme','url','img','lines','author'])
w.writeheader()
for quote in quotes:
w.writerow(quote)Here we are creating a dictionary to save all the information about a quote. Dot notation is used to access the nested structure. To access the text inside the HTML element, we use .text:
Further, we can also add, remove, modify and access tag’s attributes. We have done this by treating the tag as a dictionary:
quote['url'] = row.a['href']Then we have appended all the quotes to the list called quotes.
Finally we will generate a CSV file, which will be used to save our data.
filename = 'inspirational_quotes.csv'We have named our file inspirational_qoutes.csv and saved all the quotes in it to be used in the future also. Here is how our inspirational_quotes.csv file looks like,
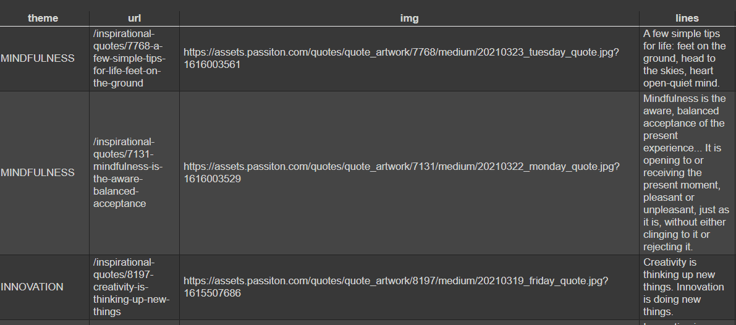
In the output above, we have only shown three rows, but there are 33 rows in reality. So this means that we have extracted a considerable amount of data from the webpage by just giving a simple try.
Note: In some cases, web scraping is considered illegal, which can cause the blockage of your IP address permanently by the website. So you need to be careful and scrape only those websites and webpages which allow it.
Why Use Web Scraping?
Some of the real-world scenarios in which web scraping could be of massive use are,
Lead Generation
One of the critical sales activities for most businesses is its lead generation. According to a Hubspot report, generating traffic and leads was the number one priority of 61% of inbound marketers. Web scraping can play a role in it by enabling marketers to access the structured lead lists all over the internet.
Market Research
Doing the right market research is the most important element of every running business, and therefore it requires highly accurate information. Market analysis is being fueled by high volume, high quality, and highly insightful web scraping, which can be of different sizes and shapes. This data can be a very useful tool for performing business intelligence. The main focus of the market research is on the following business aspects:
- It can be used to analyze market trends.
- It can help us to predict the market pricing.
- It allows optimizing entry points according to customer needs.
- It can be very helpful in monitoring the competitors.
Create Listings
Web scraping can be a very handy and fruitful technique for creating the listings according to the business types, for example, real estates and eCommerce stores. A web scraping tool can help the business browse thousands of listings of the competitor’s products on their store and gather all the necessary information like pricing, product details, variants, and reviews. It can be done in just a few hours, which can further help create one’s own listings, thus focusing more on customer demands.
Compare Information
Web scraping helps various businesses gather and compare information and provide that data in a meaningful way. Let’s consider price comparison websites that extract reviews, features, and all the essential details from various other websites. These details can be compiled and tailored for easy access. So a list can be generated from different retailers when the buyer searches for a particular product. Hence the web scraping will make the decision-making process a lot easier for the consumer by showing various product analytics according to consumer demand.
Aggregate Information
Web scraping can help aggregate the information and display it in an organized form to the user. Let’s consider the case of news aggregators. Web scraping will be used in the following ways,
Using web scraping, one can collect the most accurate and relevant articles.It can help in collecting links for useful videos and articles.Build timelines according to the news.Capture trends according to the readers of the news.
So in this article, we had an in-depth analysis of how web scraping works considering a practical use case. We have also done a very simple exercise on creating a simple web scraper in Python. Now you can scrape any other websites of your choice. Furthermore, we have also seen some real-world scenarios in which web scraping can play a significant role. We hope that you enjoyed the article and everything was clear, interesting and understandable.
If you are looking for amazing proxy services for your web scraping projects, don’t forget to look at ProxyScrape residential and premium proxies.