




How I Became A Lead “Millionaire”

~ A webscraping tale by Arya – A ProxyScrape user
Just to be clear, I am required to make a disclaimer that I am not an official representative of ProxyScrape. However, I am a huge fan and customer of their services. If you’re not already using their services, I highly recommend you do so! The following opinions and thoughts are entirely my own.
“Oh $!*^, there is no way”
That’s the exact sentiment I found myself muttering at 3 AM, grappling with the realisation that a company once as trendy as milk deliveries, something most people would consign to the era of disco music and those wild neon outfits, is still kicking around like a bad ’80s haircut – and unfortunately, it’s everywhere.
This company was the real deal in its prime. I mean, you couldn’t escape it during its heyday. Now, its name is only muttered with a hint of nostalgia in retirement homes.
“YellowPages.”
You might be wondering, “Why does this matter? Why should anyone give a damn? Why is this not a 30s TikTok with a dude playing GTA 5 on the other half of it?” Well, one of the hottest uses for web scraping is lead discovery and generation. In our capitalist wonderland where everyone’s peddling some crazy sh*t, it just makes sense to scour the internet for the suckers who’ll “HODL” and “FOMO” into your crypto timeshare that’s shaped like “half a rhombus”. And hey, just to be clear, “it’s NOT a pyramid scheme… it’s just shaped like those famous pointy things in Egypt.”
So, here’s the kicker. One of the absolute gems for B2B lead generation, in my humble opinion, is none other than YellowPages (or Yell for you “chewsday” people). Why? Well, let me break it down:
“wall of shame”: Those relics who haven’t quite caught up with the internet age are still hanging out there. Your grandpa’s business is probably chilling there, just like that SMMA you started because of TikToks and swore off within three months, which is now immortalised on Google’s business directories.
“I’m not like other girls”: While the fresh-faced scrapers believe Google Maps is the holy grail for small business leads, every savvy scraper knows that’s a load of crap- it’s saturated, every 14-year-old inspired by a certain bald man has harassed those businesses.
“like taking candy from a baby”: YellowPages’ and their derivative websites are without a shred of protection. I could scrape every single business in their directory within seconds. We’re talking about TENS OF MILLIONS of leads here.
Sure, it might not be the buzzword in marketing circles, but therein lies the opportunity. As others chase the latest trends, the savvy few recognize the potential in the forgotten corners of the internet. YellowPages might be a relic from the past, but in the world of lead generation, it’s a relic with untapped potential and a roadmap to success.
Now, you may be asking, “How would I take advantage of such an opportunity?” – Let’s walk through every step together, and hopefully, even some of you Neanderthals will be able to scrape YellowPages by the end of this.
We will approach this like we would any other website. The first step is figuring out how the f*ck the website works. This usually requires you, yes, you, to figure out how to navigate to where that juicy-juicy data is sitting. No $!*^… how do you expect to extract the data if you can’t find it pooky?!?

Shown Above: YellowPages Canada’s landing page, the unfortunate victim of this post.
As you can see above on their landing page, there are two text inputs – one for your search term and the other for the location. Let’s fill these in and do a search; I will be looking for “Dentists” in “Toronto, Ontario”.
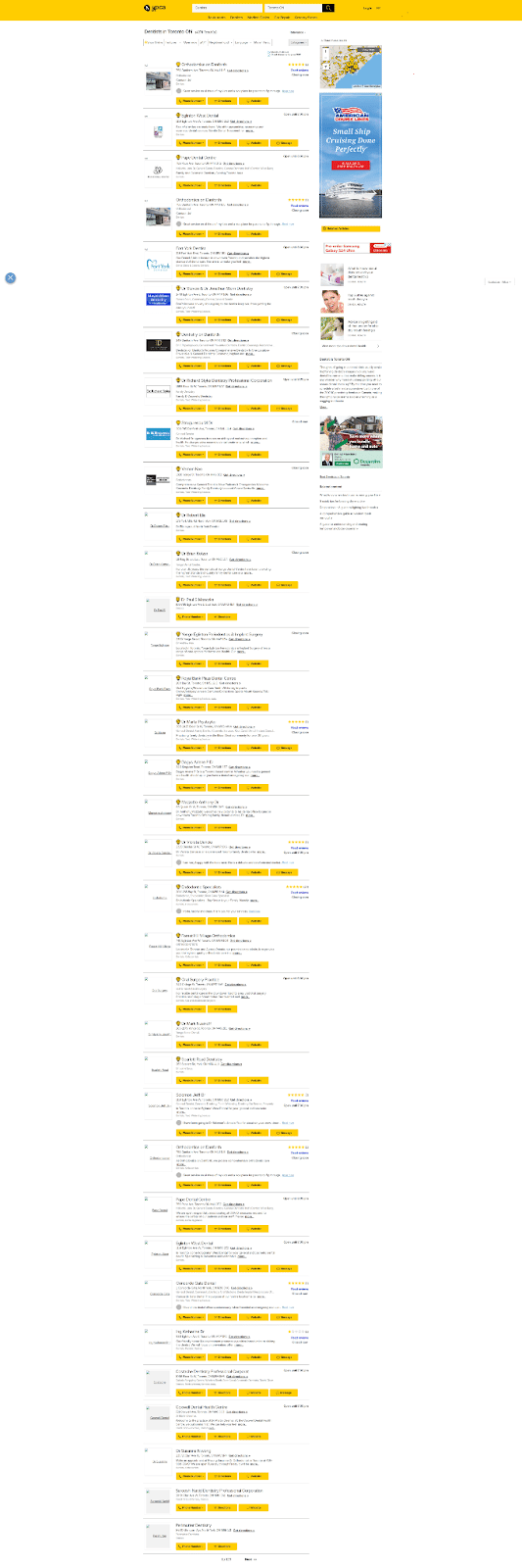
Shown Above: YellowPages Canada’s listing results page.
Once you figure out your ABCs and fill those in and manage to locate the search button AND click it (I am impressed), you should be redirected to a page like the one above which has a path like the following:
/search/si/1/Dentists/Toronto+ON
We can deduce the following path structure (this will come handy later):
/search/si/[Page Number]/[Search Term]/[Locality]+[Region Code]
Another thing to note, we’ve already located the data we want, the business listings – let’s figure out where these business listings are being loaded in from, it should be sent within the document OR fetched from an API endpoint (or if you’re wonky, and trust me I’ve seen it – websockets).
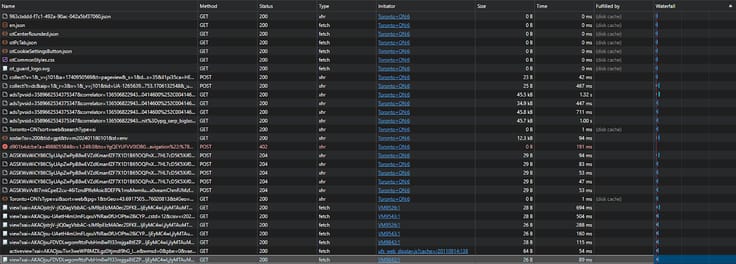
Shown Above: The fetch/XHR requests originating from the page. (Spoiler: the data isn’t in any of them.)
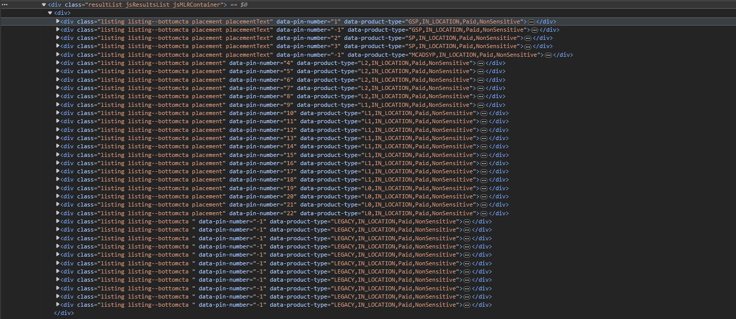
Shown Above: The business listings within the document. (OMGEEE The data was in fact within the document.)
As we sifted through the API requests, looking for the data, it was proven futile. We then turned our attention to the HTML. Now, here’s a little nugget of insight for you – after “navigating the digital landscape for over a decade”, I knew instinctively that the data was within the document, thanks to the pages’ snappy responsiveness.
Let’s be real, though. Given YellowPages’ status as a phonebook company desperately seeking relevance and, more crucially, revenue, it’s improbable they’re flaunting cutting-edge tech stacks. The chances of them hiring developers who flaunt flannels and have fifty React-based to-do apps on their resume are slim to none. So, are we genuinely shocked that the webpage is static?
Nevertheless, the listings within the page are contained within a div, extractable using the selector “div.resultList“. Each individual listing, conveniently nested within the aforementioned element, can be extracted with the selector div[itemtype="http://schema.org/LocalBusiness]
I’ll leave you to figure out how to individually extract the data beyond this level of granularity; otherwise, we’d be here forever. Use the “itemprop” attribute — it should significantly ease the process for you.
Now, to automate extraction: You should paginate through the results using the URL (recall the path structure we discussed earlier), extracting elements and data from each page until you hit an empty page. I personally opted to use Rust for this project as it’s fast and provides easy parallelization (which will be important in a second), leveraging the “reqwest” and “select” crates to handle the heavy lifting. And here’s a few pro tips: remember to rotate your user agent, set your referrer correctly, use a proxy, and PLEASE don’t DDOS them.
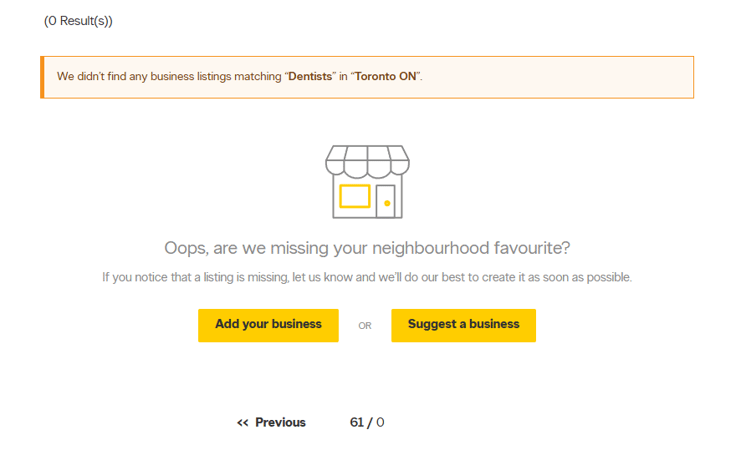
Shown Above: YellowPages’ empty result page.
Your script should be good to go now. But how can we elevate this even further? Let’s put our singular combined brain cell to work and ponder… “Do we need to sequentially request each page?” Absolutely not. YellowPages makes it remarkably easy for us to parallelize this process by providing the number of pages available for the query – hint, hint, wink, wink.
Shown Above: YellowPages’ page count at the bottom of the results’ page.
There is one caveat to this parallelization strategy, though: While YellowPages may suggest more than 60 pages of results exist, attempting to access any page beyond 60 on the results will not render. Therefore, set a hard cap for your parallelization at 60. Assuming adequate bandwidth and computing power – every result page should be scraped in the same time it would take you to scrape one page within the sequential model.
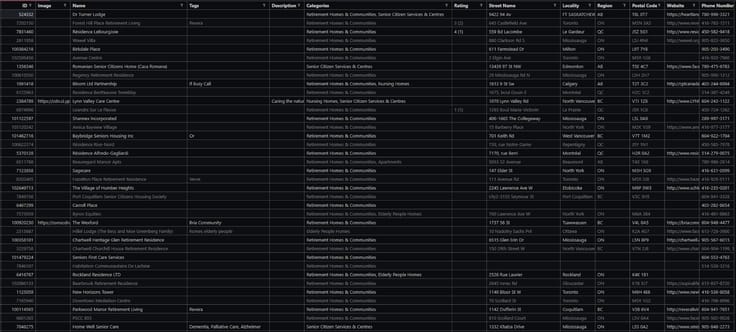
Shown Above: Example of extracted YellowPages’ listing data.
Now, you might be wondering, was this clickbait? What does the “millionaire” bit have to do with all this? Well, if you’ve followed along and now possess a functional script, I may or may not be able to personally attest that nothing is stopping you from theoretically iterating through every city in Canada and pulling every business listing from a query within said city from YellowPages. This data may literally hold a dollar value in the millions if properly augmented, but it’s also quite literally millions of businesses within their directory that are now within your reach.
YellowPages may evoke memories of a bygone era, its potential for B2B lead generation remains a hidden treasure trove in the digital landscape. By navigating the quirks of its static web interface, scraping data from this seemingly outdated platform unveils a vast array of business leads. The overlooked and underutilised nature of YellowPages makes it a unique opportunity.
My only goal is this blog post will not leave you thinking “the real treasure was the friends we made along the way” – I hope this both demonstrated the unique opportunities that exist especially with the skill set so many of us take for granted and also hopefully, served as an interesting read for those of you who are experienced within this field, and gave insight to those of you who aren’t.
As always, stay safe, use protection, and for the love of god… don’t do something where the FBI will be on your ass – well.. in this case it would be the RCMP.

Shown Above: The Canadian FBI equivalent – the RCMP.